
AI Data Security: Stop Leaks at the Moment Data Enters an AI Tool
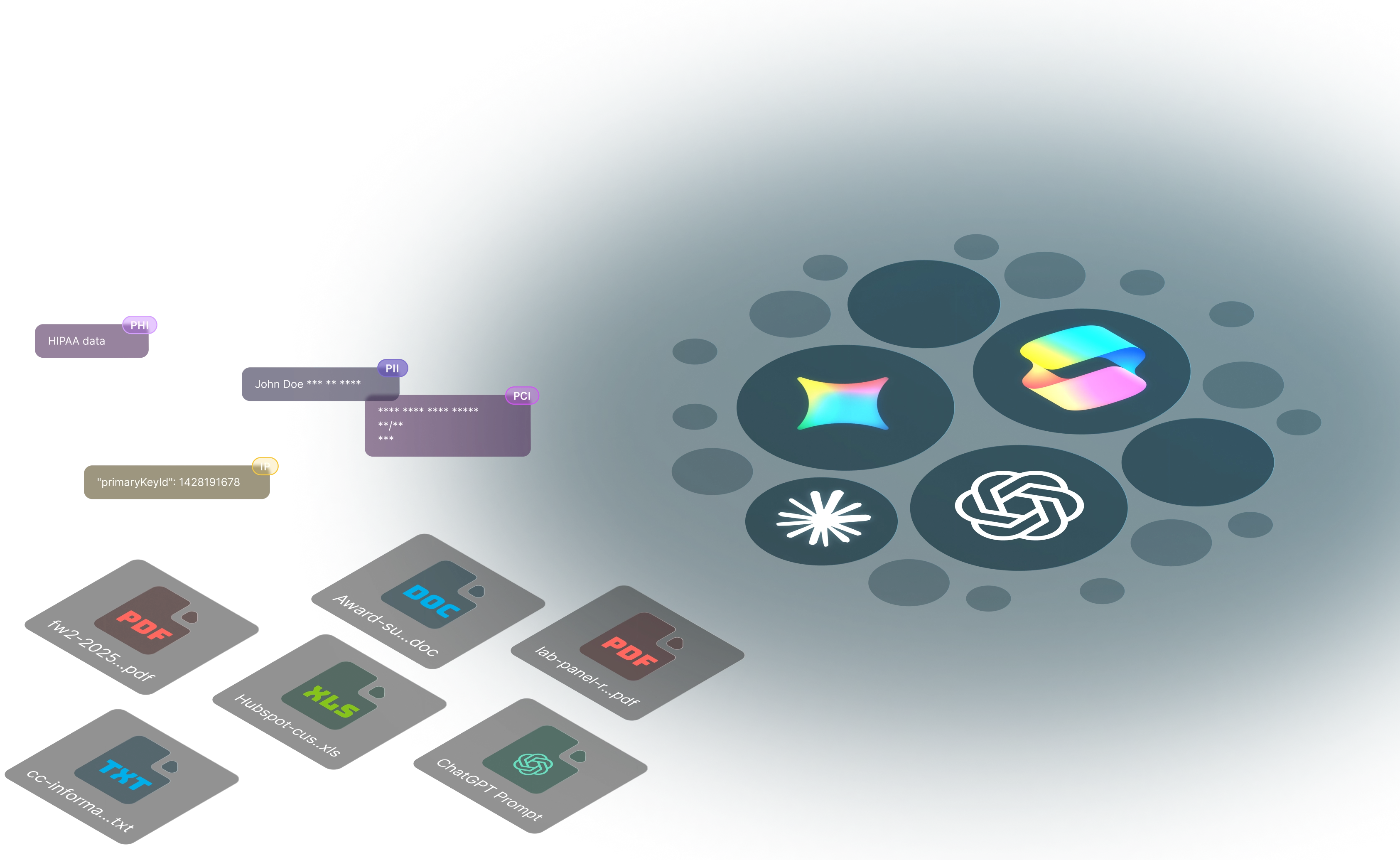
AI data security is not a network problem, and it is not a data-at-rest problem. It is a moment-of-use problem. The risk happens the instant an employee pastes a customer list into a chatbot or uploads a contract to a personal AI account. If your controls only watch the network or scan files sitting in storage, you miss the one moment that matters. dope.security closes that gap by inspecting the prompt and the upload on the device, before the data ever leaves, using Dopamine DLP and three layers of AI governance. This is what AI data security has to mean in 2026.
What is AI data security?
AI data security is the practice of keeping sensitive data from leaking into AI tools, and keeping the AI tools your people use under enterprise control. That covers two things: stopping confidential data from going into a prompt or an upload, and making sure the AI account receiving it is a sanctioned corporate tenant rather than someone's personal login. Both have to be true at the same time, because allowing the right tool with the wrong data, or the right data on the wrong account, both end in exposure.
The reason this is hard is that AI use looks like ordinary web traffic. A prompt to ChatGPT, Claude, or Gemini is an HTTPS request to a domain you probably want to allow. The sensitive part is buried inside the encrypted session, in the text of the prompt and the bytes of the upload. To govern it you have to see inside that session at the moment it happens. For the full strategic picture, our complete guide to AI visibility and governance is the hub this article sits under.
Why traditional data security misses AI
Most data security tooling was built for two worlds that AI does not live in. The first is the network world, where a proxy or DNS filter decides what destinations are allowed. The second is the data-at-rest world, where a scanner crawls your file stores and SaaS tenants looking for exposed sensitive files. Both are useful. Neither sees an employee typing a quarterly forecast into a chatbot.
DNS filtering blocks domains, so it can block an AI site entirely or allow it entirely, and nothing in between. That is a blunt instrument that either kills productivity or permits the leak. A cloud proxy can see more, but only if it decrypts the session, and even then it typically needs a separate data-protection add-on to read prompt content, sitting behind a higher pricing tier. Data-at-rest scanners and posture tools are valuable for finding exposed files, but by the time data is at rest somewhere, the prompt has already been sent. We walk through the same blind spot from the angle of employees uploading sensitive files to AI.
The result is a stack that watches the perimeter and the storage but goes quiet at the exact moment of use. That is the gap AI data security has to fill.
Where does the risk actually happen?
The risk happens at the endpoint, inside the encrypted session, at the moment the prompt is sent or the file is selected for upload. That is the only place where you can see the data, identify it as sensitive, and decide whether to allow, monitor, or block, before it leaves the company.
dope.security inspects there. Because the Fly Direct secure web gateway runs as an agent on the device and performs SSL inspection locally, it can read the content of an AI prompt and the contents of an upload as they happen. Dopamine DLP then classifies that content through zero-retention APIs and applies your policy in real time, with Block, Monitor, and Off modes. The classification is zero-retention, so the data used to make the decision is not retained or used to train a model. Dopamine DLP holds US Patent 12,464,023, and you can read the product overview in meet Dopamine DLP.
The three layers of AI data security
Governing AI well takes more than a single block rule. dope.security uses three layers that work together, and each answers a different question.
Layer one is discovery. You cannot govern what you cannot see. Shadow IT and shadow AI discovery shows you which AI apps are in use across the organization and which accounts are corporate versus personal. Start with AI visibility across every AI app and the practical detail in shadow AI detection and governance.
Layer two is web policy. The SWG decides who can reach which AI tools and under what conditions. This is where you allow the tools your business runs on and block the ones you have not vetted, without the all-or-nothing bluntness of DNS.
Layer three is tenant control. Cloud Application Control lets you allow the corporate AI tenant while blocking personal accounts on the same domain. This is the hardest test in the category, and it is the one that actually stops the leak. We cover the mechanism in one-click AI blocking and shadow AI detection.
Layered on top, Dopamine DLP inspects the content itself, so even on an approved tool with an approved account, a forecast or a customer record does not slip into a prompt. Discovery, web policy, tenant control, and content inspection together are what zero-risk productivity looks like in practice.
How the approaches compare
| AI data security need | DNS filtering | Cloud proxy + DLP add-on | Data-at-rest scanner | dope.security |
|---|---|---|---|---|
| Discover which AI tools are in use | Partial | Partial | No | Yes |
| Allow corporate AI, block personal, same domain | No | Partial, higher tier | No | Yes, on-device |
| Inspect data inside an AI prompt | No | Add-on, decrypt required | No | Yes, Dopamine DLP |
| Zero-retention classification | N/A | Varies | Varies | Yes |
The gap is consistent: perimeter and storage tools see around the moment of use, not the moment itself. On-device inspection sees the prompt and the upload as they happen.
Building an AI data security policy that people will follow
Technology enforces a policy, it does not replace one. The strongest programs pair the three layers above with a written standard that names which tools are approved, what data is off-limits, and what happens when someone tries to send it. Our AI usage policy template and enforcement guide gives you a starting point you can adapt.
The key is to make the policy enforceable without making it punitive. Monitor mode is useful here: turn it on first, see what data is actually heading into AI tools, then tighten to Block on the categories that matter. That sequence builds the case for the policy with evidence instead of assumptions, and it avoids the productivity cliff that comes from blocking everything on day one. For tool-specific controls, see how we handle ChatGPT data leaks and Claude data leaks.
Which AI tools should you worry about most?
The honest answer is all of them, but the harder truth is that the tools change faster than any block list can keep up. ChatGPT, Claude, Gemini, and Microsoft Copilot are the obvious ones, and each has both an enterprise tier and a free personal tier that look identical on the wire. That is the trap. A policy that names today's four tools is out of date the moment a fifth gains traction, which is why discovery has to run continuously rather than as a one-time audit.
Two categories get overlooked. The first is AI that lives inside developer tools, like IDE copilots that can send code and secrets to a model without anyone opening a browser. The second is API-based AI, where an application calls a model directly. Browser-only controls miss both, because nothing renders in a browser tab. On-device inspection sees the egress regardless of which application originates it, which is the only way to keep coverage as the tool list grows. The same problem surfaced with the rise of MCP servers as a new form of shadow IT, where dozens of new AI-connected domains appeared with no one watching.
Why on-device beats browser-only and API-gateway approaches
Two popular shortcuts fall short for the same architectural reason. A browser isolation or browser-extension approach can only govern what happens in a managed browser, so it is blind to desktop AI apps, IDE copilots, and anything that does not run in that browser. An AI gateway aimed at developers governs your own applications' calls to a model, which is useful, but it is not employee governance and it does not see a person pasting data into a chatbot.
On-device inspection sits below both. Because the dope.security agent inspects all egress at the endpoint, it covers the browser, the desktop app, the IDE, and the API call with one control. There is no separate AI product to license, no browser to mandate, and no gap between the tools you thought you covered and the tools your people actually use. That breadth is exactly why a single endpoint agent is the right place to enforce AI data security, the same reason it is the right place to enforce web and SaaS policy.
What good looks like in production
The test of AI data security is whether it works at scale without slowing people down. Because dope.security runs on the device with an agent under 100 MB of RAM and no backhaul, the inspection adds no network detour, so governing AI does not cost users speed. A Fortune 100 company scaled the dope.security agent from 900 to over 18,000 devices in a matter of weeks, with policy pushing in real time at the individual and group level, detailed in the Fortune 100 deployment story. That is the bar: AI controls that deploy in days, enforce in real time, and do not punish the user for the security team's peace of mind.
It also means you are not buying a separate AI product. Discovery, web policy, tenant control, and prompt-level DLP all live in the same console as the SWG, under one agent and one policy model. For a broader view of the risk landscape, enterprise AI security and shadow AI risk connects the dots.
The takeaway
AI data security is decided in a single moment: when the prompt is sent and the file is chosen. Tools that watch the network or scan storage are looking everywhere except that moment, which is why so many AI controls feel like theater. The fix is to inspect on the device, where you can read the prompt, identify the sensitive data, confirm the account is corporate, and act, all before anything leaves. That is what dope.security does with Dopamine DLP and three layers of AI governance, and it is why the leak gets stopped at the source instead of discovered after the fact. For the full program view, the complete AI visibility and governance guide ties discovery, policy, and content inspection together. Start a free trial or book a 20-minute demo to see corporate-versus-personal AI control and prompt-level DLP running on a real device.
.jpg)
.jpeg)
.jpeg)

